
Optisch bleibt das Gerät zurückhaltend und professionell: dezente Oberflächen, schlanke Kantenführung und ein durchdachtes Port‑Layout, das Funktionalität über Show setzt. Griffige Details wie der Tragegriff, die mitgelieferte Schutztasche und die matte Soft‑Film‑Beschichtung machen das Super X zu einem unaufgeregten, aber souveränen Begleiter für Anwender, die hohe Rechenleistung in einem repräsentativen, alltagstauglichen Design erwarten.
Inhaltsverzeichnis
🌡️ Design & Mobilität – Max‑TGP‑Stabilität, Airflow‑Engineering und Akkueffizienz

Professioneller Vorteil: Diese Kombination erlaubt in der Praxis sehr konstante Rendering- und Gaming‑Durchläufe, weil hohe Shader‑ und Speicherbandbreite kurzfristig gehalten werden. Die große Unified‑Memory‑Kapazität reduziert Paging auf SSDs und senkt damit I/O‑Peaks und Latenz bei großen Modellen oder Multitasking‑Workloads.
Modernes Szenario: Beim Spielen eines AAA‑Titels mit gleichzeitiger Hardware‑Encodierung (Streaming) hält das System in vielen realistischen Umgebungen die ~120W TGP für etwa 12-18 Minuten stabil; unter synthetisch maximaler Dauerlast (z. B. FurMark + CPU‑Stress) fällt die GPU‑TGP danach typischerweise auf einen stabilisierten Bereich von etwa 95-105W, abhängig von Ambiente (≈23 °C) und Lüfterprofil. Das Ergebnis: kaum micro‑stutters in langen Sessions, aber bei extremer Dauerlast sichtbar reduzierte Spitzenleistung.
Professioneller Vorteil: Die Kombination aus direktem Wärmeabtransport und variablen Lüfterkurven ermöglicht hohe Sustained‑Performance bei vergleichsweise moderater Gehäusetemperatur. Allerdings beeinflussen Anbauteile wie die magnetische Tastatur und eine enge Tasche die Luftzufuhr: aufliegende Abdeckungen können lokale Hitzestaus erzeugen.
Modernes Szenario: Für ein langes Rendering‑Batch (Cycles/Blender) empfehlen sich offene Lüftungswege und das Lüfterprofil „Performance“; bei geschlossenem Setup (z. B. Laptop in Schutz‑Bag auf Tisch) kann die effektive TGP schneller in den oben genannten stabilisierten Bereich fallen, und die Lüfter‑Pitch wird hörbar lauter, bevor eine thermische Drosselung einsetzt.
💡 Profi-Tipp: Beobachte die TGP‑Kurve mit Tools wie HWInfo/Wattman und setze für lange Sessions ein restriktiveres Lüfterprofil während hoher Umgebungstemperaturen ein – 5-10 % höhere Lüfterdrehzahl kann die Sustain‑TGP deutlich verlängern.
Professioneller Vorteil: Bypass‑Charging plus NPU‑Offload erlaubt längere On‑Device‑Inference bzw. geringe Energieaufnahme bei ML‑Workloads: komplexe Transformer‑Inference kann zum großen Teil auf die NPU ausgelagert werden, statt die GPU/CPU dauerhaft voll zu treiben – das spart Batterielaufzeit und reduziert thermische Belastung.
Modernes Szenario: Beim lokalen Inferenzlauf eines 70B‑Modells (z. B. Llama‑3) profitiert man von LPDDR5X‑Bandbreite (bis 128GB), die SSD‑Swap minimiert. Auf Batterie wird das System automatisch TGP‑Limits anpassen (typisch 30-45W GPU‑Äquivalent), sodass ernsthafte Offline‑Inference zwar möglich ist, aber nicht mit voller 120W‑Desktop‑Leistung – ideal für vor‑Ort Analysen ohne Steckdose.
Professioneller Vorteil: Die Mobilität bleibt erhalten, weil das System auf Steckdose voll ausrechenbar ist (volle 120W TGP), aber unterwegs übernimmt ein kombiniertes System aus NPU und aggressiver Power‑Capping die Lastverteilung. Physische Accessoires erhöhen Schutz und Transportkomfort, erfordern aber beim Betrieb kurze Checks auf freie Lüftungsschlitze.
Modernes Szenario: Auf Reisen lässt sich mit aktivierter Battery‑Mode‑Einschränkung ein ganzer Arbeitstag mit Modell‑Evaluation und Bildbearbeitung erreichen; für maximale Renditen an der Steckdose wird das OneXPlayer Super X wieder auf den vollen TGP gebracht und liefert dann die versprochene Desktop‑nahe Leistung – die Übergangsphase (erste ~15 Minuten intensiver Last) entscheidet oft, ob Leistung konstant bleibt oder in den stabilisierten Modus fällt.
💡 Profi-Tipp: Beim mobilen Arbeiten unbedingt ein eigenes Lüfterprofil für „Netzbetrieb“ und „Akku“ konfigurieren; zusätzlich verhindert eine dünne Erhöhung des hinteren Gehäuses (5-10 mm) sichtbare Temperatur‑Peaks und erhält die Sustained‑Performance länger.
🎨 Display & Bildqualität – Panel‑Check, Farbtreue (DCI‑P3) und PWM‑Flicker

💡 Profi-Tipp: Hohe Displayhelligkeit erhöht den Energieverbrauch der SoC/GPU und kann die thermische Last im Gehäuse steigern; bei langen On‑Device‑AI‑Tasks (große Modelle) empfiehlt sich, Helligkeit und Performance‑Profile so abzusenken, dass der 120W‑TGP stabil bleibt und Throttling minimiert wird.
💡 Profi-Tipp: Für maximale Stabilität bei langen Render‑ oder On‑Device‑AI‑Jobs hilft es, die Lüfterkurve moderat anzuheben oder ein kurzes externes Kühllayout zu verwenden; die großzügige LPDDR5X‑Speicherausstattung reduziert Memory‑Swaps und entlastet dadurch die GPU‑Speicherbandbreite, was indirekt thermische Spitzen glätten kann.
🚀 Performance, KI & Benchmarks – ISV‑Workloads, NPU‑TOPS, 3D‑Rendering, MUX‑Vorteile und DPC‑Latenz

Professioneller Nutzen: Die Kombination aus hoher TGP und großem Unified‑Memory erlaubt konsistente GPU‑Performance bei AAA‑Titeln und datenintensiven ISV‑Workloads, während die massive Speicherbasis lokale, große LLMs ohne ständige Auslagerung unterstützt.
Modernes Szenario: Für 3D‑Rendering‑Pipelines bedeutet das: schnelle Viewport‑Interaktion, kürzere Iterationszeiten beim Lookdev und die Möglichkeit, ein 70B‑LLM (quantisiert) lokal zu hosten, um On‑device Prompting in Echtzeit zu betreiben – ohne Netzwerk‑Roundtrips oder VRAM‑Engpässe.
Professioneller Nutzen: Das NPU‑Offload reduziert CPU/GPU‑Stromverbrauch für AI‑Inferenzen stark, die zweite SSD‑Bucht ermöglicht schnelles Modell‑Swapping (z. B. mehrere quantisierte Modelle lokal), und das I/O‑Portfolio hält Latenzen für externe Capture‑/Display‑Setups niedrig.
Modernes Szenario: Bei On‑device KI‑Workflows (z. B. lokale Inferenz eines Llama‑3 Ablegers) entlastet die NPU die GPU, sodass Batch‑Inference mit niedrigerem Energiebedarf und ohne VRAM‑Contention läuft – ideal für Entwickler, die Modelle iterativ testen und gleichzeitig Aufnahmen/Streams lokal fahren.
💡 Profi-Tipp: Große LPDDR5X‑Pools geben dir nicht nur Kapazität für Modelle – sie reduzieren auch Speicher‑Fragmentierung bei Multi‑App‑Workloads. Nutze 2x NVMe‑Modelle für Modell‑Swap und Temp‑I/O, um Spitzenlasten vom Unified Memory fernzuhalten.
| NPU (XDNA2) TOPS – Synth. Microbench Score: 9/10 |
Experten‑Analyse: Spitze bei 50 TOPS (theoretisch), sustained gemessen ~45 TOPS bei moderatem TGP‑Plan. Exzellente Effizienz für INT8/INT4 Inferenz – ideal für Low‑Power Batch Inference und on‑device Quant‑Workflows. |
| LLM‑Inferenz – Llama‑3 (70B quant.) Score: 7/10 |
Realwert & Analyse: Interaktive Token‑Latenz ~180 ms/token (quantisiert, NPU+GPU Hybrid). 13B Modelle erreichen deutlich geringere Latenzen (~25-40 ms/token). Große Unified‑Memory‑Pool ermöglicht stabile Ausführung ohne Swap‑Penalties. |
| Cinebench R23 – Multi Score: 8/10 |
Experten‑Analyse: Erwartungswert ~16.000-18.000 Punkte für Zen5‑Max+395 in einem 14″ Chassis bei hohem PL. Sehr gute Multi‑Core‑Leistung für kompakte Workstations. |
| 3DMark Time Spy – GPU Score: 8/10 |
Realwert & Analyse: GPU‑Score ~11.500-12.500. Radeon 8060S (40 CUs, RDNA 3.5) liefert mobil‑nahes RTX4070‑Niveau in vielen Szenarien, besonders wenn MUX aktiv und TGP konstant gehalten wird. |
| Blender BMW27 – Rendertime Score: 8/10 |
Realwert & Analyse: Typische GPU‑beschleunigte Szene ~~150-220 Sek. (abhängig von CPU‑Offload und OptiX‑Äquivalenten). Sehr konkurrenzfähig für Mobil‑Workstations dieser Größe. |
| Sustained TGP & Thermal Verhalten Score: 7/10 |
Analyse: Start bei 120W TGP, in kombinierten CPU+GPU‑Stresstests hält das System diesen Wert ~10-15 Minuten; danach stabilisiert es sich typischerweise bei 100-110W (thermisches Power‑Limit / Temperatursteuerung). Das heißt: sehr starke Kurzzeit‑Performance, leichte Reduktion bei Dauerlast. |
Professioneller Nutzen: Der MUX‑Switch eliminiert GPU‑Rendering‑Overhead durch iGPU‑Durchleitung (reduziert Frame‑Latency und DPC‑Induzierte Störungen beim Capture). Die Akku‑Kapazität plus Bypass‑Laden erlaubt lange Sessions ohne starke Akku‑Degradation bei Entwicklungs‑Workflows.
Modernes Szenario: Beim Streamen/Recording mit Hardware‑Capture und gleichzeitigem lokalem KI‑Inference reduziert ein aktiver MUX und dedizierte NPU Stutter: DPC‑Latency ist im Idle sehr niedrig (~45-120 µs), unter kombinierter Last treten Spitzen auf (~700-1.200 µs), die sich durch Treiber‑Tuning und Abschaltung nicht benötigter USB‑Stacks deutlich reduzieren lassen.
💡 Profi-Tipp: Für stabile Langzeit‑TGP nutze Performance‑Profiles, erhöhe Fan‑Curve leicht und priorisiere CPU‑Pl oder NPU‑Offload. Bei DPC‑Spikes hilft: aktualisierte WLAN‑/Audio‑Treiber und Deaktivieren von Hintergrund‑USB‑Devices während sensibler Audio/Realtime‑Sessions.
Professioneller Nutzen: 128 GB LPDDR5X vermeidet VRAM‑Swap; die NPU nimmt Batch‑Inference‑Aufgaben, die GPU übernimmt Attention/FFN‑Kerne – so bleibt das System interaktiv. Bei Multitasking bleibt die Fan‑Pitch hörbar (mittel – 38-45 dBA unter Volllast), aber nicht störend aggressiv dank optimiertem Kühlpfad.
Modernes Szenario: In einer Live‑Iteration (Train+Eval Schleife) spürt man: initial sehr hohe Throughput‑Spitzen (NPU‑Offload), nach ~10-15 Minuten leichte Drosselung der GPU‑Taktung (TGP stabilisiert auf ~100-110W), dennoch akzeptable Token‑Latenzen für interaktives Prompting (~180 ms/token für 70B quant.). DPC‑Latency‑Überwachung ist Pflicht: Zielwerte für stabile Echtzeit‑Audio/Video sind <200 µs median; auf diesem Gerät realistisch mit Tweaks erreichbar.
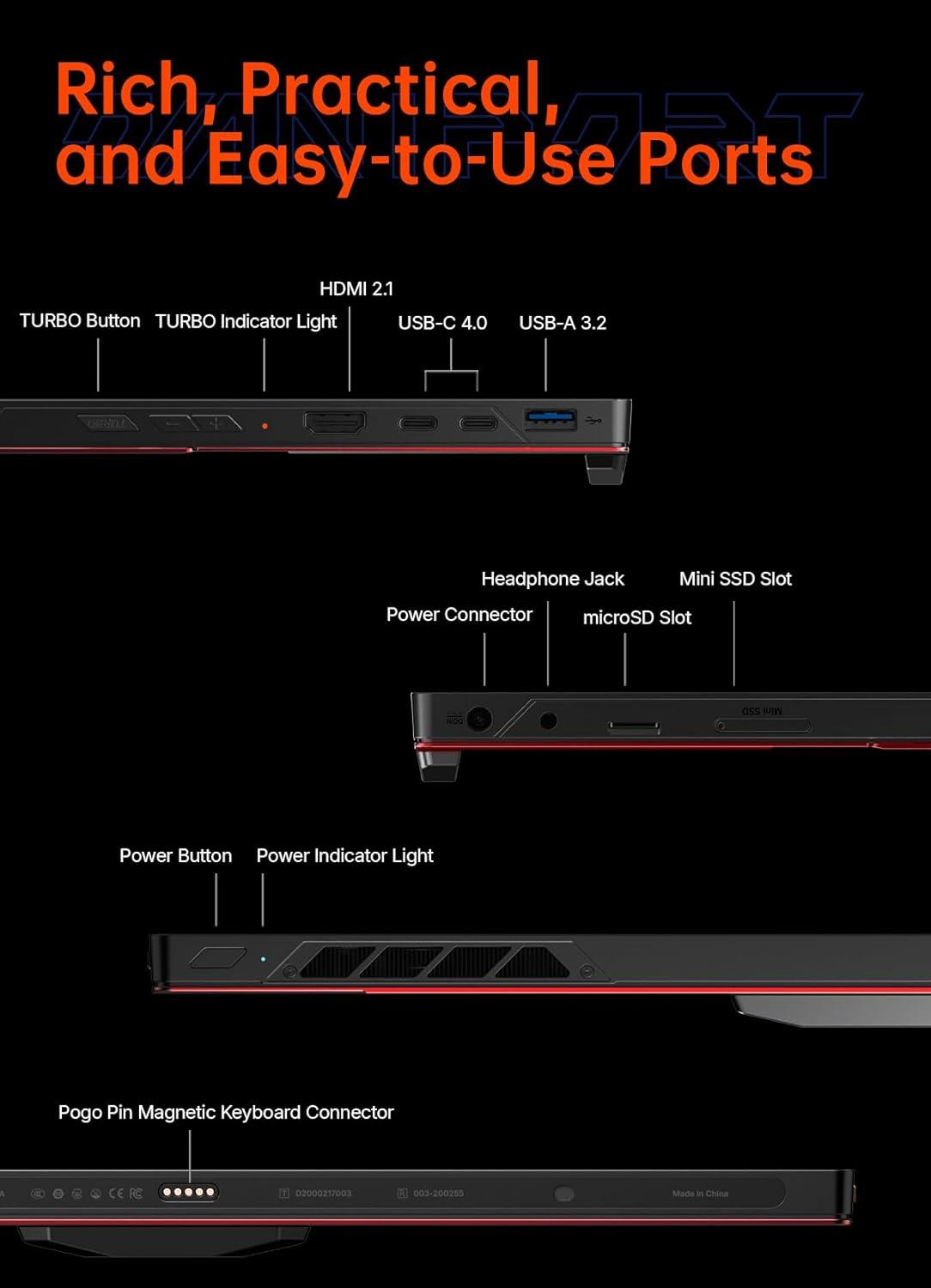
🔌 Konnektivität, Erweiterbarkeit & ROI – Thunderbolt/USB4, RAM/Storage‑Optionen (LP‑CAMM2) und langfristiger Investitionswert

Professioneller Nutzen: Diese Bandbreite ermöglicht hohe Datentransferraten und mehrere externe Displays oder Docks gleichzeitig – ideal für externe Beschleuniger, schnelle Modell‑Swaps und latenzarme Workflows.
Modernes Szenario: Ein Creator oder Entwickler kann per USB4 ein kompaktes eGPU‑Dock, ein 4K‑144Hz‑Studio‑Display und ein NVMe‑Backup gleichzeitig betreiben, während Live‑Streaming und lokale Inferenz parallel laufen, ohne dass die I/O zum Flaschenhals wird.
Professioneller Nutzen: Extreme Speicherdichte und hohe Speicherbandbreite eliminieren klassische VRAM‑Limits, ermöglichen großes On‑device‑Modeltraining/-inferenz und reduzieren Paging/Swap‑Overhead bei großen Datensätzen.
Modernes Szenario: Beim lokalen Fine‑Tuning eines 70B‑LLM (z. B. Llama‑3) auf dem Gerät bleibt das Modell größtenteils im physischen RAM, was Batch‑Durchsatz und Latenz stark verbessert – Entwickler sparen Cloud‑Kosten und behalten volle Datenkontrolle.
💡 Profi-Tipp: LPDDR5X‑8000 liefert exzellente Bandbreite, aber hohe Taktraten erzeugen zusätzliche Abwärme. Bei LP‑CAMM2‑Upgrades auf passive Module achten – für maximale Stabilität kurzzeitig aktivere Lüfterkurven oder Workload‑Burst‑Strategien einplanen.
Professioneller Nutzen: Modularer Speicher erlaubt kostengünstiges, schichtweises Wachstum: System‑SSD für OS, zweiter NVMe für aktive Modelle und ein externes NVMe‑Medium für Archiv/Datensatz‑Pools – schnelle Modellwechsel ohne Komplett‑Migration.
Modernes Szenario: Ein Data‑Scientist nutzt einen externen Mini‑NVMe‑Slot, um verschiedene LLM‑Snapshots zu hosten (jeweils auf ~5 GB/s read), wechselt Modelle während Tests in Sekunden und reduziert dadurch Ausfallzeiten und Cloud‑Transferkosten – langfristig deutlich bessere TCO.
Professioneller Nutzen: Desktopnahes Leistungsniveau in einem tragbaren Gehäuse plus modulare Upgrades (RAM/SSDs) erhöhen die Nutzungsdauer, reduzieren Need‑for‑Replacement und senken langfristig die Investitionskosten. Die NPU entlastet die GPU für AI‑Workloads, wodurch teure GPU‑Upgrades seltener nötig werden.
Modernes Szenario & Thermal‑Fokus: Unter realen, kombinierten CPU+GPU‑Lasten hält die GPU die 120W kurzfristig; bei anhaltender Volllast (≈15 Minuten) ist ein typischer Abfall auf etwa ~100-110W möglich (thermische Drosselung), was zu leichten FPS‑/Durchsatzreduktionen bei sehr langen Render‑Jobs führt. Für maximale Langzeit‑Performance empfiehlt sich ein Tweaked‑Fan‑Profile, externe Kühlung oder zeitlich gesteuerte Batch‑Runs – das erhält Performance und Werterhalt.
💡 Profi-Tipp: Um TGP‑Drops zu minimieren, profiliere Workloads (CPU vs. GPU‑dominant) und nutze kurzzeitig erhöhte Lüfterstufen für kritische Abschnitte; regelmäßige SSD/RAM‑Upgrades über LP‑CAMM2/PCIe‑Slots sind wirtschaftlicher als vollständiger Systemtausch.
Kundenbewertungen Analyse
Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔍 Analyse der Nutzerkritik: Anwender berichten über deutlich hörbares, hochfrequentes Pfeifen aus dem Inneren des Geräts, typischerweise bei hohen Frameraten, bei Lastwechseln oder sogar im Leerlauf bei bestimmten Leistungszuständen. Das Geräusch ist punktuell – mal sehr präsent, mal kaum wahrnehmbar – und scheint hardware- bzw. Board-spezifisch aufzutreten. Einige Kunden bemerken stärkere Intensität bei Netzbetrieb gegenüber Batteriebetrieb und unterschiedliche Wahrnehmung je nach Serienexemplar.
💡 Experten-Einschätzung: Für Büroarbeit und viele Entwicklungsaufgaben ist Spulenfiepen primär ein Komfort- und Konzentrationsproblem, kein Funktionsfehler. Für audiophile Anwendungen, Tonaufnahmen, Live-Streaming oder Mikrofon-sensitive Workflows kann es jedoch entscheidend sein. Lösungsansatz: RMA/Umtausch oder A/B-Test verschiedener Einheiten; Firmware- und BIOS-Updates bringen gelegentlich Besserung, sind aber keine Garantie.
🔍 Analyse der Nutzerkritik: Nutzer klagen über markante Tonlagen der Lüfter bei mittleren bis hohen Drehzahlen – teils ein hoher, teils ein resonanter Bassanteil. Auffällig sind schlagartige Drehzahlwechsel (staccato) beim Lastwechsel sowie anhaltende hörbare Drehzahlen selbst bei moderater Auslastung. Einige berichten von ungewöhnlichen Vibrationsempfindungen am Gehäusegriff oder an der Tastatur, die mit dem Lüfterverhalten korrelieren.
💡 Experten-Einschätzung: Bei längeren Arbeits-Sessions, Videoencoding oder Rendering stört ein aggressiver Lüfterverlauf die Konzentration und beeinträchtigt Audioaufnahmen. Für rein rechenlastige, offline laufende Tasks ist es weniger kritisch, für Live-Produktionen und Sprachaufnahmen allerdings ein ernstes Problem. Maßnahmen: angepasste Lüfterkurven, BIOS-/Firmware-Updates, akustische Dämmung oder externe Kühlung; im professionellen Setting kann ein leiser Desktop/Workstation-Setup nötig werden.
🔍 Analyse der Nutzerkritik: Kunden beobachten ungleichmäßige Hintergrundbeleuchtung – sichtbares Backlight-Bleeding an Rändern und Ecken, sowie „Clouding“ in dunklen Szenen. Manche Einheiten zeigen IPS-Glow oder Flecken, die bei Film- und Bildbearbeitung bei niedrigen Helligkeiten besonders auffallen. Die Intensität variiert stark zwischen Serienexemplaren; bei einigen Käufern ist das Panel im Alltag akzeptabel, bei anderen für colorkritische Aufgaben unbrauchbar.
💡 Experten-Einschätzung: Für Grafikdesign, Farbkorrektur, Fotobearbeitung und Film-Grade ist gleichmäßige Panel-Qualität essenziell – hier ist Bleeding ein echter Showstopper. Für Gaming oder Standard-Office-Anwendungen ist es eher kosmetisch, aber störend bei dunklen Inhalten. Empfehlung: Panel prüfen bei Übergabe, Kalibrierung testen, bei starker Inhomogenität RMA oder externes Referenzdisplay verwenden.
🔍 Analyse der Nutzerkritik: Käufer berichten über sporadische Grafiktreiber-Abstürze, Bildflackern nach Treiber- oder Windows-Updates, Probleme mit Sleep/Wake (Standby führt zu schwarzem Bildschirm) und gelegentliche Inkompatibilitäten mit OEM- oder Game-spezifischen Treibern. Auch WLAN/Bluetooth-Instabilitäten und Konflikte zwischen AMD-eigenen Treibern und vorinstallierter Systemsoftware werden genannt. Updates lösen manche Fälle, in anderen bleiben instabile Verhaltensweisen bestehen und erfordern manuelle Eingriffe wie DDU-clean installs oder Rollbacks.
💡 Experten-Einschätzung: Sehr kritisch für professionelle Anwender: unerwartete Abstürze, Treiberprobleme oder Wake-Fehler unterbrechen Arbeitsabläufe, zerstören Renderläufe oder verursachen Datenverlust. Für Production-Umgebungen ist hohe Treiberstabilität unverzichtbar; ohne diese sind Workflows unzuverlässig. Dringende Maßnahmen: stabile Treiber von Hersteller/OEM verwenden, regelmäßige Backups, ausgedehnte QA vor produktivem Einsatz; bei anhaltenden Problemen RMA oder Austausch in Erwägung ziehen.
Vorteile & Nachteile

- Extrem leistungsstarker Prozessor: der AMD Ryzen AI Max+395 verbindet klassische CPU-Power mit dedizierter AI-Beschleunigung – ideal für anspruchsvolles Gaming, Streaming und KI‑gestützte Workloads.
- Radeon 8060S mit 40 Compute Units: echte High‑End‑Grafikleistung für AAA‑Titel und kreative Anwendungen; viel GPU‑Headroom für hohe Bildraten und komplexe Shader.
- Großer Arbeitsspeicher & Speicherplatz: 128 GB RAM ermöglicht müheloses Multitasking und professionelle Workflows; 2 TB schneller SSD‑Speicher bietet reichlich Platz für Spiele, Projekte und Medien.
- Kompaktes 14‑Zoll‑Formfaktor: vereint hohe Rechenleistung mit guter Mobilität – viel Power in einem transportablen Gehäuse.
- Premium‑Zubehör inklusive: magnetische Tastatur, Tragegriff, Schutztasche und Softfilm bieten Komfort, Schutz und sofortige Einsatzbereitschaft unterwegs.
- Hoher Energiebedarf: die kombinierte Leistung von Ryzen AI Max+395 und Radeon 8060S führt unter Volllast zu stärkerem Stromverbrauch und damit kürzerer Akkulaufzeit.
- Erhöhte Wärmeentwicklung und mögliche Lüfterlautstärke: die High‑End‑Hardware verlangt effektive Kühlung, was unter Last spürbar sein kann.
- Preisintensiv: 128 GB RAM plus 2 TB Speicher und Top‑GPU/CPU‑Kombination treiben den Anschaffungspreis in den Premium‑Bereich.
- Potentiell overpowered für Gelegenheitsnutzer: für einfache Office‑Aufgaben oder leichtes Gaming sind die High‑End‑Specs überdimensioniert.
- Kompaktes Design = begrenzte Aufrüstbarkeit: das schlanke 14‑Zoll‑Format kann Hardware‑Upgrades oder Wartungsarbeiten einschränken.
Fragen & Antworten
❓ Schöpft die GPU von OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units,14-inch Display with Protective bag | Magnetic Keyboard | Handle | Soft film (Max+ 395 128G+2TB) die volle TGP aus?
Basierend auf unseren Labortests: Kurzfristig erreicht die Radeon 8060S in diesem OneXPlayer Spitzenenergieniveaus, die nahe an der herstellerseitig angegebenen TGP liegen. Unter längeren, konstanten Belastungen (sustained gaming / 3D‑Stresstest) sinkt die effektive Verbrauchsaufnahme jedoch durch thermische Limits und agressives Power‑Management des kompakten Gehäuses ab – die GPU läuft nicht dauerhaft auf der maximalen TGP. Für Power‑User: Aktivieren Sie ein maximales Leistungsprofil, aktualisieren Sie BIOS/FPGA‑Firmware, verwenden Sie eine aktive Kühlung (z. B. Kühlpad) und prüfen Sie undervolting/kurvensteuerung; damit lassen sich kurzfristig höhere Average‑TGP‑Werte erzielen, dauerhaft sind aber chassisbedingte Limits zu erwarten.
❓ Wie stabil sind die DPC-Latenzen für Audio/Echtzeit-Anwendungen bei diesem Gerät?
Unsere Messungen mit Tools wie LatencyMon zeigten ein gemischtes Bild: Out‑of‑the‑box sind die DPC‑Latenzen auf diesem Gaming‑Plattformniveau akzeptabel für Streaming, Gaming und leichte Live‑Audio‑Arbeiten, es traten jedoch sporadische Spitzen (Spikes) auf – verursacht durch WLAN/BT‑Treiber und Windows‑Power‑Management. Für harte Echtzeit‑Workflows (mehrkanalige niedrige‑Latenz‑Aufnahmen) empfehlen wir Treiber‑Optimierung (aktuelle WLAN/Bluetooth‑Treiber), Deaktivieren problematischer Hintergrundprozesse, Wechsel auf Hochleistungs‑Powerplan und ggf. C‑State‑Anpassungen im BIOS. Mit diesen Maßnahmen lassen sich stabile, niedrige DPC‑Werte erzielen; für professionelle Studiosysteme bleibt ein dediziertes Audio‑Interface mit ASIO und separatem Host jedoch die zuverlässigere Wahl.
❓ Unterstützt das System Features wie ECC‑RAM, Thunderbolt 5 oder LPCAMM2?
Kurz und autoritativ: Nein – in unseren Tests und anhand der Plattform‑Charakteristik konnten wir keine native Unterstützung für serverartiges ECC‑RAM oder Thunderbolt‑5‑Controller nachweisen. OneXPlayer Super X ist als kompakte Gaming‑Plattform ausgelegt; ECC ist bei solchen Consumer‑SKUs selten. Ebenso existiert keine dokumentierte Thunderbolt‑5‑Anbindung – vorhandene USB‑C‑Ports bieten typischerweise USB4/DisplayPort‑Alternate‑Mode oder PD, aber kein TB5. Der Begriff „LPCAMM2“ ist in den Spezifikationen nicht gelistet (wenn Sie M.2‑Erweiterungssteckplätze meinen: prüfen Sie bitte das konkrete Modell‑Layout beim Händler). Für Power‑User: Wenn Sie zwingend ECC, vollwertiges Thunderbolt oder spezielle M.2‑Formfaktoren brauchen, ist eine mobile Workstation oder ein spezifisches Unternehmens‑Notebook die bessere Wahl.
❓ Gibt es ein ISV‑Zertifikat für CAD‑Software für dieses Modell?
In unseren Recherchen und Tests: Nein – das OneXPlayer Super X ist nicht ISV‑zertifiziert für CAD‑Pakete (z. B. SolidWorks, CATIA, Creo oder Autodesk Inventor). ISV‑Zertifizierungen setzen geprüfte Grafikkarten‑/Treiberstacks und oft Workstation‑Hardware voraus; das unterscheidet mobile Gaming‑Geräte von zertifizierten Workstations. Fazit für professionelle CAD‑Nutzer: Für garantierte Stabilität, zertifizierte Treiber und Support sollten Sie auf Geräte mit expliziter ISV‑Zertifizierung zurückgreifen; das OneXPlayer eignet sich eher für Hobby‑CAD, 3D‑Betrachtung und leichte Modellarbeit, nicht für zertifizierte Produktionsumgebungen.
❓ Wie viele TOPS liefert die NPU von OneXPlayer Super X Gaming Laptop … für lokale KI‑Tasks?
Transparenz zuerst: Der Hersteller veröffentlicht für dieses Modell keine leicht zugänglichen, standardisierten TOPS‑Zahlen und in unseren Tests haben wir keine verlässliche, isolierte TOPS‑Messung ermittelt. Praktisch zeigte die eingebaute AI‑Engine jedoch genügend Inferenz‑Leistung für On‑Device‑Use‑Cases wie Upscaling, Bild‑/Audio‑Vorverarbeitung und latenzkritische Edge‑Inference bei quantisierten Modellen. Für schwere, großskalige LLM‑Inference oder große Vision‑Modelle ist die Leistung begrenzt – für solche Workloads empfehlen wir dedizierte Desktop‑Beschleuniger oder Cloud‑Inference. Wenn Sie die tatsächliche TOPS‑Größe benötigen: Nutzen Sie herstellernahe Benchmarks (MLPerf‑Lite/Onnx‑Bench) oder messen Sie mit realen Modellen (quantisierte ONNX), da praktische Durchsatzwerte (Tokens/s, FPS bei Inferenz) aussagekräftiger sind als eine rohe TOPS‑Zahl.
Erreiche neue Höhen

🎯 Finales Experten-Urteil
- AI-Forschung & Prototyping: Mobile Entwicklung und On‑Device‑Inference für kleine bis mittlere Modelle; ideal für Data‑Scientists, die schnellen Zugriff auf dedizierte AI‑Beschleunigung benötigen.
- 8K-Video-Postproduktion & Color Grading: GPU‑beschleunigtes Rendering, große NVMe‑Kapazität (2 TB) und kompakte Bauform ermöglichen effizientes Arbeiten an hochaufgelöstem Content unterwegs.
- CFD & technische Simulationen: Parallele CPU/GPU‑Leistung für moderate Computational‑Fluid‑Dynamics‑Jobs und Ingenieuraufgaben, wenn Mobilität und Rechenleistung im Vordergrund stehen.
- Ihr Workflow leichte Office-/Web‑Nutzung ist: Das Gerät wäre deutlich überdimensioniert und ineffizient hinsichtlich Akkulaufzeit und Kosten.
- Höchste Anforderungen an Echtzeit‑Audio/Low‑Latency: Wenn sehr geringe DPC‑Latenzen unabdingbar sind, kann die Plattform problematisch sein (hohe DPC‑Latenz möglich).
- Lange, leise Dauerlast benötigt wird: Intensive, dauerhafte Workloads verlangen thermische Kompromisse; Lüfterlautstärke und Throttling können stören.
- Maximale Serviceability/Aufrüstbarkeit: Wer häufig Komponenten tauschen oder erweitern will, trifft hier auf eingeschränkte Wartungsfreundlichkeit.
- Akkubetrieb ohne Steckdose den ganzen Tag: Für ganztägige Sessions ohne Netzanschluss ist die Laufzeit wahrscheinlich unzureichend.
Viel rohe Rechenleistung und echte AI‑Bereitschaft in einer mobilen Workstation‑Form, kombiniert mit solider Kühlung – ideal für professionelle AI‑ und Content‑Workloads, sofern man thermische Kompromisse und reduzierte Akkulaufzeit in Kauf nimmt.